Генерируем таймкоды для YouTube из транскрипта с помощью AI
Таймкоды для YouTube AI не изобретёт — и не должен. Точное время начала темы — это не то, что модель «знает»: она не видела секунд, она видела текст. Просить её выдать 12:00 — значит просить выдумать правдоподобное число. И она его выдумывает. Поэтому таймкоды на длинных стримах систематически встают криво: не модель плохая, а задача поставлена неправильно.
Правильно — разделить заботы. Где меняется тема, описывает модель: это про смысл. Когда именно она меняется, находит обычный детерминированный код по реальным меткам из распознавания речи. Я зову это split-concern, и без него таймкоды уезжают на минуты.
Разберу на живом примере. У меня залиты три эфира из серии про модель Claude Fable 5, и на всех трёх агент-критик нашёл и починил сдвиги. Вот как.
Весь путь — от видео до готовых таймкодов на YouTube — одной схемой:
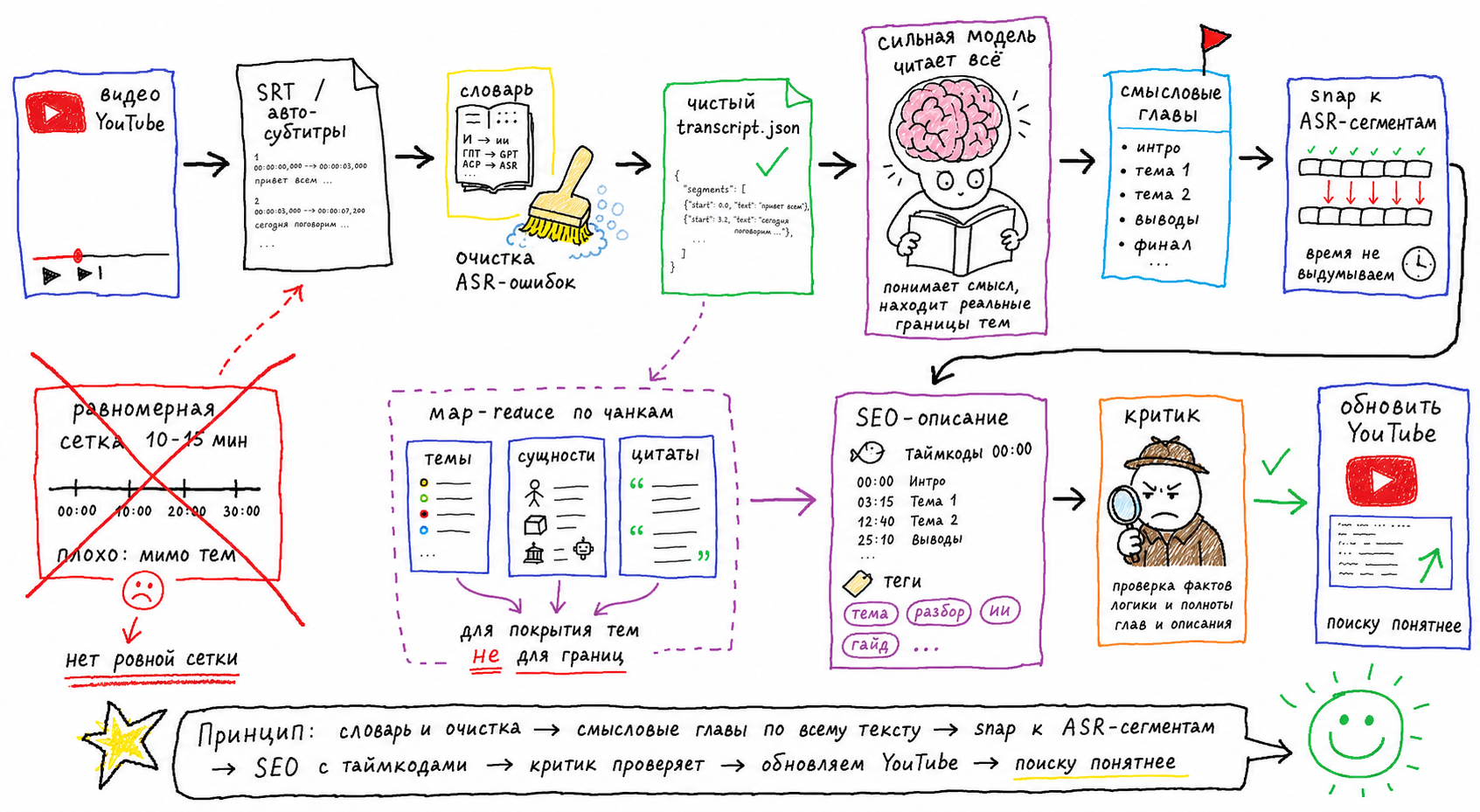
Проблема: равномерная сетка
Первая версия выглядела разумно. Я попросил агента взять транскрипт и нарезать его на куски «по естественным границам тем», чтобы из них собрать таймкоды. Под капотом это крутилось на слабой модели — Haiku, на сыром тексте, одним проходом. Вернулось вот что: 0:00, 5:00, 12:00, 20:00. Ровная сетка с круглыми числами.
Выглядит логично — и в этом ловушка. Модель не «видит» время. Она видит поток текста и генерирует то, что статистически похоже на список таймкодов: округлённые, равномерно разнесённые отметки. 5:00 и 12:00 смотрятся как настоящие, потому что таймкоды обычно так и выглядят. Но это паттерн, а не измерение.
А реальные сегменты в распознанной речи начинались на 291.7, 307.3 секунды и подобных «некруглых» местах. Отметки уехали на минуты: зритель жмёт на «Computer Use», попадает в середину разговора про что-то другое. Покрытие при этом честные сто процентов — каждая секунда видео попадает под какой-то таймкод, дыр нет. Поэтому старая проверка ничего не ловила: она смотрела на покрытие, а не на то, совпадают ли отметки с реальными переходами тем.
Тут же вылезла вторая болячка длинного контекста — «found in the middle». У внимания модели U-образный профиль: начало и конец транскрипта она держит, а середина проседает. На двух-трёхчасовом стриме это значит, что таймкоды из середины — самые неточные. Наивный одиночный проход по всему тексту тут проигрывает по построению.
Map-reduce, которым я раньше разбивал транскрипт на куски, эту болячку лечит для покрытия тем — каждый кусок прочитан внимательно. Но для точных отметок он плох: куски не знают друг про друга, и стык между ними — это не обязательно стык темы.
Принцип split-concern
Я перестал просить модель делать две работы сразу. Теперь у задачи два эшелона, и каждый занят своим.
Первый эшелон — модель, и она отвечает только за смысл: где в разговоре меняется тема. Промпт даёт ей весь транскрипт построчно, и каждая строка снабжена реальной меткой HH:MM:SS: текст. Дальше — явный запрет округлять: таймстамп нужно скопировать из строки, а не сочинить. То есть модель не генерирует время, она его выбирает из входа. Это ровно приём из Chapter-Llama (CVPR 2025): когда метки поданы прямо в текст и модель их цитирует, точность попадания в правильную секунду поднимается примерно с 52% до 98%. Структурированный ввод превращает «угадай число» в «выбери из списка».
Попросил Claude Code (Opus):
Прочитай весь транскрипт (дан построчно с реальным HH:MM:SS). Разбей на смысловые куски по 5–10 минут и для каждого дай таймкод начала. Режь на естественных границах тем, не по таймеру. Таймстамп копируй из строки — не округляй, не выдумывай 05:00 или 12:00. Для каждой отметки укажи, почему она здесь, и приведи дословный фрагмент из транскрипта.
Второй эшелон — код, и он отвечает только за время. Даже когда модель честно цитирует строку, она может зацепить соседнюю или слегка промахнуться. Поэтому после неё работает детерминированный скрипт — буквально строк тридцать. Он берёт каждую отметку, которую назвала модель, и притягивает её к ближайшему реальному началу сегмента из распознавания речи: считает расстояние до всех стартов сегментов и берёт минимальное. Это «snap» — привязка. Если модель округлила до 12:00, а настоящий сегмент стартовал на 11:51.4, скрипт сдвинет таймкод на реальную метку. Время — задача без творчества, и решает её код, а не повторные попытки LLM угадать.
Именно snap в прошлой версии пайплайна и отсутствовал — отсюда тот самый баг с равномерной сеткой. Модель выбирала, код не поправлял, дрейф жил.
Вот те же два мира рядом:
БЫЛО: модель «изобретает» время (одна работа на двоих)
транскрипт ──▶ Haiku, один проход ──▶ 0:00 │ 5:00 │ 12:00 │ 20:00
▲ ▲ ▲
круглые, равномерные, мимо тем
реальные старты сегментов: …291.7 307.3 428.9…
└── таймкоды уехали на минуты ──┘
СТАЛО: split-concern (смысл и время разведены)
транскрипт (HH:MM:SS построчно)
│
▼
┌────────────────────┐
│ модель: где тема │ ▶ выбирает таймстамп из строки
│ меняется (СМЫСЛ) │ (не округляет, цитирует)
└─────────┬──────────┘
│ отметки-кандидаты
▼
┌────────────────────┐
│ код: ближайший │ ▶ argmin по расстоянию
│ реальный старт │ до старта сегмента
│ сегмента (ВРЕМЯ) │
└─────────┬──────────┘
▼
таймкоды на реальных границах ──▶ adversarial-критикGlossary-fix: шаг ноль
Перед всем этим есть шаг, без которого подписи таймкодов получаются кривыми ещё до нарезки. Распознавание речи коверкает имена собственные: «Mythos», «Majesty», «ElevenLabs» приезжают в транскрипт исковерканными. А подпись таймкода строится из текста — значит искажение течёт прямо в название.
Поэтому порядок жёсткий: сначала словарь, потом таймкоды. На первом эфире агент прогнал 97 замен по глоссарию ещё до нарезки. Только на исправленном тексте имеет смысл искать переходы — иначе чиним симптом в подписях вместо причины в тексте. А вопрос «какие темы вообще достойны отдельной отметки» — это уже другая задача про релевантность, не про время.
Adversarial-критик как предохранитель
Snap притягивает отметку к реальному сегменту — но он ничего не знает о том, правильная ли это точка по смыслу. Он чинит арифметику времени, а не семантику. Это разные задачи, поэтому проверку смысла я вынес в отдельного агента-критика.
Критик — отдельный субагент. Он читает окно ±60 секунд вокруг каждого таймкода и спрашивает себя: тема действительно меняется ровно тут? Если нет — ищет реальный переход рядом и копирует точную метку из строки.
Попросил Claude Code (Opus):
Ты придирчивый аудитор таймкодов. Для каждого таймкода прочитай окно ±60 секунд вокруг него и проверь: тема реально меняется ровно тут? Если нет — найди реальный переход и скопируй точный таймстамп из строки. Скажи, что подвинуть и почему.
На трёх эфирах Fable 5 критик поймал три разных сдвига, refine их починил, все три залиты:
- День 1: таймкод «Computer Use / AppleScript» стоял на
0:45:48, а реальный старт темы —0:50:02. Почти четыре минуты разницы: в промежутке шёл бенч про cost-per-task, и зритель попадал в него вместо обещанной темы. - День 2: таймкод «Personal Corp» оказался привязан не туда — тема начиналась на
3:08:45, а отметка стояла на3:20:49. - День 3: таймкод «Зачем экономить лимиты» сидел внутри анонса воркшопа — его надо было сдвинуть с
1:01:31на1:03:18.
Все три — именно смысловые сдвиги, которые snap пропустил бы: метка-то к реальному сегменту привязана, просто не к тому. Поэтому критик нужен как отдельный слой, а не как настройка скрипта.
Кто на какой модели и почему
Пайплайн — это не один агент, а стопка субагентов, и каждый сидит на своей модели. Принцип простой: сильную модель туда, где нужен глобальный контекст и суждение; дешёвую — где задача узкая; код — где задача детерминированная.
- Смысловая карта — Opus. Тут модель должна удержать весь транскрипт разом и увидеть реальные переходы. Слабая срывается в сетку — Haiku на сыром тексте и выдал то самое
0:00 / 5:00 / 12:00. Эти границы задают скелет всему дальше, на них не экономлю. - Snap — вообще не модель. Привязку таймкода к реальному сегменту делает детерминированный код. Время — не творческая задача, LLM тут только мешает.
- Разбор кусков — Sonnet. Когда границы найдены, по каждому куску отдельный субагент достаёт, о чём он. Кусок небольшой, задача узкая — Opus избыточен, Sonnet дешевле и справляется.
- Критик — снова Opus. Проверка «тема правда меняется тут?» требует рассуждения не слабее самой нарезки. На критике держу сильную модель, как и на границах.
- Refine — Sonnet. Правка точечная, по готовым замечаниям критика. Тяжёлая модель ни к чему.
Это и есть стек моделей вместо одной. Везде Opus — дорого и незачем; везде Haiku — получишь ту самую сетку. Полезность тут не в том, какая модель, а в том, как разложена задача вокруг неё: правильная модель на правильном шаге выходит и дешевле, и точнее, чем одна модель на всё.
Одна команда
Самое приятное — что весь этот путь я не дирижирую руками. Это один скилл, и агент ведёт его от начала до конца сам: скачать запись, получить транскрипт, прогнать словарь, построить смысловую карту тем, сделать snap по реальным сегментам, пропустить через критика, вставить готовые таймкоды в описание и опубликовать. Без ручных остановок между шагами.
Я даю одну команду — дальше смотрю. Это та же логика, по которой у меня агенты собирают трек для AI-радио за одну сессию: вся настоящая работа — в форме задачи и инфраструктуре вокруг, а не в моём микроменеджменте по ходу.
Выводы
- Split-concern — не про красоту, а про точность. Пока модель делала обе работы сразу, таймкоды уезжали на минуты. Развёл смысл и время — дрейф пропал в корне.
- Детерминированный snap дешевле, чем гонять LLM угадывать. Тридцать строк кода привязывают отметку к реальному сегменту надёжнее и без расхода токенов на повторные попытки модели попасть в правильное число.
- Критик — дешёвый предохранитель. Один субагент с окном ±60 секунд ловит смысловые сдвиги, которые snap по построению пропускает. Три эфира — три пойманных промаха.
- Таймкоды по смыслу удобнее всем. Зритель прыгает по реальным переходам тем, а не по округлённой сетке; поиск получает осмысленные, не съехавшие метки. Точность тут — не косметика, а условие, чтобы таймкодами вообще пользовались.
Подписаться на обновления — @sereja_tech