Слои контекста: организуем файлы по скорости изменения
Структура папок в проекте определяет, какой контекст попадёт в окно агента. Lifecycle-split — группировка файлов по скорости изменения, а не по теме — снижает токен-шум и повышает качество решений без смены модели. Я перестроил один проект с 66 файлов в корне до 6, сократил контекст root с 46k до 20k токенов. Агент стал принимать решения точнее.
Агент ведёт себя странно — виновата не модель
Типичная ситуация: агент делает не то. Выбирает устаревшие данные, путает текущий оффер с историческим, предлагает создать файл, который уже существует в другой папке.
Первая реакция — модель тупая, нужна другая. Или контекст маленький, нужно окно побольше. А проблема в том, что агент читает не тот контекст. Всё лежит в одной куче: стратегия рядом с черновиками, каноничные данные рядом с устаревшими отчётами. Для агента все файлы одинаково релевантны.
developertoolkit.ai описали паттерн: агент потратил 8000 токенов на файл в 2000 строк и выбрал неправильный участок кода. Не потому что модель слабая — контекст не был подготовлен.
Context engineering — не промпт, а класс
Andrej Karpathy назвал это context engineering: «The delicate art and science of filling the context window with just the right information». Не «побольше», а «именно то, что нужно».
Разница с prompt engineering — как разница между хорошим вопросом и правильно организованным классом. Промпт — это вопрос. Context engineering — всё, что вокруг: какие материалы на парте, какие убраны в шкаф, какой порядок на доске.
И вот ключевое: размер окна не решает проблему контекста — он её маскирует. Миллион токенов в окне не поможет, если агент читает 167 тысяч токенов мусора. Он всё равно потеряется.
Есть полезное разделение: stable vs volatile context. Stable — то, что не меняется месяцами: архитектура, принципы, каноничные данные. Volatile — задачи, черновики, промежуточные результаты. Когда они живут в одной папке — агент не знает, что свежее, а что устарело.
Как плохая структура убивает агента
clawsouls.ai описали симптом: без persistent identity кодовая база начинает выглядеть так, будто её писали пятьдесят слегка разных разработчиков. Каждая сессия — новый стиль, новые решения, новые конвенции. Агент не помнит, что делал вчера.
Marvin Ma на dev.to назвал это Context Collapse: два часа отладки, утром агент ничего не помнит. Контекст сессии исчез. Результаты не закрепились в структуре проекта.
Проблема архитектурная, не модельная. Stateless-агент не помнит между сессиями. Единственная «память» — файлы проекта. Если файлы не организованы по смыслу, агент каждый раз начинает с нуля в хаосе.
6 принципов контекстной архитектуры
Я сформулировал эти принципы, когда перестраивал personal-corp — проект, где AI-агенты управляют стратегией, операциями и задачами. Но принципы работают для любого проекта, где агент принимает решения на основе файловой структуры.
1. Контекст не живёт одной кучей — нужна архитектура слоёв
Не «одна папка docs/», а слои с разной глубиной и частотой обновления. Стратегические документы обновляются раз в квартал. Задачи — каждый день. Каноничные данные — раз в неделю. Если они лежат рядом, агент тратит токены на всё подряд.
2. Сырая дата — слабый контекст
Транскрипты звонков, выгрузки метрик, черновики отчётов — это raw data, не готовый контекст. Агент получит пользу, когда данные прошли через отбор, нормализацию и упаковку под задачу. Один подготовленный JSON кормит агентов лучше, чем десять необработанных выгрузок.
3. Каждому слою — свой тип производного контекста
Стратегии нужны паттерны, риски, динамика. Исполнению — конкретная задача, ограничения и критерии выполнения. Одно представление на всё = каша.
4. Главное — не хранение, а маршрутизация
Проблема не «где хранить». А: что куда попадает, что не должно попадать, что идёт в долгую память, что остаётся шумом. Маршрутизация важнее самого хранилища — описать правила «что куда» в CLAUDE.md ценнее, чем создать красивую иерархию без правил.
5. Цель — качество решений, не скорость закрытия тасков
Агент чаще принимает стратегически верные решения. Замечает слабые сигналы и повторы ошибок, потому что читает только канон вместо 66 файлов. Меньше шума — меньше ошибок.
6. Выигрывает тот, кто управляет контекстом
Не тот, кто накопил больше данных. А тот, кто раньше выстроил архитектуру, научился фильтровать и подаёт нужное представление в нужный слой в нужный момент. Это конкурентное преимущество — контекст важнее модели.
8 слоёв контекста
Принципы — это мышление. А вот конкретные слои, из которых состоит любой AI-проект:
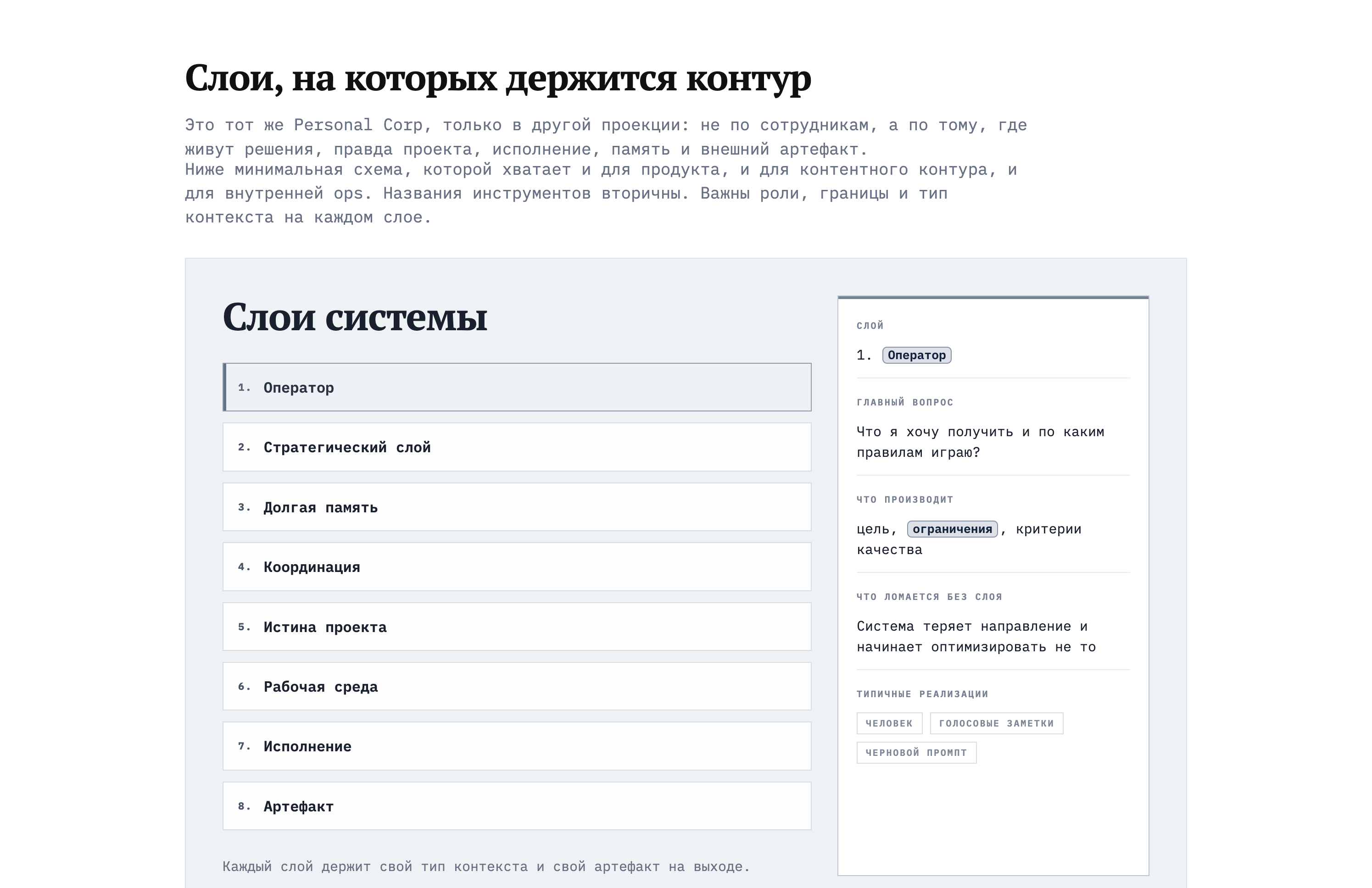
У каждого слоя — своя скорость изменения. Стратегия обновляется раз в квартал. Координация — каждый день. Артефакт — при каждом деплое.
Когда всё свалено в одну папку, агент не видит этих слоёв. Он читает strategy.md и task-файл недельной давности как равноценные документы. А они из разных миров.
Lifecycle-split — это по сути раскладка слоёв по папкам. Каждая папка = один-два слоя. Каждый слой = своя скорость обновления.
Практика: lifecycle-split на personal-corp
Теория — полдела. Вот как это выглядело на практике.
До: 66 файлов, ~167k токенов. Root = 46k (28% всего контекста). Research, advisor reports, каноничные документы — всё в одной куче. Агент при каждом запросе читал всё. На стратегический вопрос подтягивал операционные черновики. На задачу по деплою — три отчёта совета директоров.
Я попросил агента (Claude Code, Opus 4.6):
Четыре субагента за одну сессию прошли все 66 файлов. Выяснилось: 42 из них — балласт. 23 устаревших артефакта шумели в контексте, 11 research-файлов должны были жить в отдельном репо, 8 task-файлов болтались без привязки к issue. Остальные 24 были рабочими — но тонули в этом шуме.
Следующий промпт:
После: 6 файлов в root + 4 папки. Root ~ 20k токенов.
ДО: 66 файлов, ~167k токенов
всё в корне + docs/ + research/ + archive/
┌─────────────────────────────────────────────────┐
│ ROOT (46k tokens, 28% контекста) │
│ │
│ strategy.md systems.md departments.md │
│ advisor-*.md research-*.md plan-*.md │
│ task-*.md draft-*.md old-*.md │
│ │
│ → стратегия, отчёты, задачи, черновики, │
│ устаревшее — ВСЁ в одной куче │
└─────────────────────────────────────────────────┘
│
▼ lifecycle-split
ПОСЛЕ: 6 файлов в root + 4 папки, ~20k root
┌──────────────────┐
│ ROOT (канон) │ ← обновляется: раз в квартал
│ │
│ strategy.md │ агент читает ВСЕГДА
│ systems.md │
│ departments.md │
│ flows.md │
│ registry.md │
│ CLAUDE.md │
└──────┬───────────┘
│
┌────┼────────┬──────────┐
▼ ▼ ▼ ▼
┌────┐┌─────┐┌──────┐┌─────────┐
│prod││ ops ││ work ││ archive │
│uct/││ ││ ││ │
│ ││infra││tasks ││read-only│
│ ││ ││+issue││ │
│rare││мес. ││нед. ││никогда │
└────┘└─────┘└──────┘└─────────┘
Принцип: lifecycle, не topic. Все файлы в папке меняются с одинаковой скоростью.
- ROOT = корпоративный канон: стратегия, системы, департаменты. Обновляется раз в квартал. Агент читает это при каждом запуске.
- product/ = продуктовые описания. Меняется редко — раз в месяц при запуске нового оффера.
- ops/ = инфраструктура, метрики, конфиги. Меняется раз в пару недель.
- work/ = задачи, привязанные к GitHub Issues. Живут дни-недели. Создаются и закрываются.
- archive/ = read-only. Ничего не меняется, агент не читает без прямого запроса.
Финальный штрих — маршрутизация:
Агент добавил в CLAUDE.md таблицу: какой тип файла в какую папку, что запрещено создавать в root, куда уходят research-артефакты (всегда в отдельный research-corp, не сюда). work/ файлы обязаны ссылаться на GitHub Issue — нет issue, нет файла.
По-моему, самый показательный побочный эффект — что случилось с CLAUDE.md. Я сократил свой с 800 до 150 строк, и compliance агента вырос. vibemeta.app независимо пришли к тому же: их CLAUDE.md ужался с 847 до 127 строк с аналогичным результатом. Короткий CLAUDE.md лучше соблюдается агентом, чем длинный. Меньше правил — выше compliance.
«Context is a budget. Spend it like rent money, not casino chips» — rentierdigital.xyz.
Microsoft ACE: валидация подхода
Но это не только мой опыт с одним проектом в марте 2026. Microsoft Research в рамках проекта ACE показали: правильная подготовка контекста даёт +10.6% на бенчмарках без смены модели. Те же самые модели, те же задачи — другая подготовка контекста.
Они зафиксировали две системные проблемы. Brevity Bias — модель предпочитает короткие ответы, когда контекст перегружен. Context Collapse — качество решений падает нелинейно с ростом нерелевантного контекста. Не «чуть хуже», а резко хуже после определённого порога.
Lifecycle-split атакует обе проблемы: сокращает объём контекста до релевантного и убирает шум, который триггерит Brevity Bias.
Инфраструктура решает больше, чем модель
Я повторяю это в каждом посте, потому что это так. Можно потратить месяц на промпт-инжиниринг, а можно попросить агента за час пересобрать папки — и получить больший эффект.
Три действия:
- Посмотри на root своего проекта. Сколько файлов? Сколько из них агент реально использует при каждом запуске?
- Раздели по lifecycle: что меняется раз в квартал, что каждый день, что не меняется никогда.
- Пропиши маршрутизацию в CLAUDE.md — не «где что лежит», а «что куда попадает и что запрещено».
Выигрывает не тот, у кого лучший агент. А тот, кто управляет контекстом.
Подписаться на обновления — @sereja_tech