Перешёл на Claude Fable 5: цены, effort, кейсы
Вчера, 9 июня, Anthropic выпустила Claude Fable 5 — новый класс моделей под названием Mythos, четвёртый в иерархии после Haiku, Sonnet и Opus. Для вайбкодера это значит одно: появилась новая рабочая модель, на которую есть смысл пересесть, если задача поставлена чётко. По прайсу вдвое дороже Opus, но отдача с одной задачи выходит выгоднее — и ниже я разберу почему.
Я провёл стрим прямо в день релиза. Читал пресс-релиз вслух, тыкал Computer Use и поймал отличный анти-кейс с 32 агентами, а агент тем временем собрал четыре проекта — мультиплеер-шутер с деплоем за полчаса, арканоид с управлением рукой, клон Majesty и Chrome-расширение. Всё, о чём пишу дальше — оттуда, со скриншотами и ссылками на работающие игры.
Все эксперименты стрима — в публичном репозитории serejaris/claude-fable: каждый проект в своей папке, рядом оригинальный промпт.
Иерархия и цены
Раньше верхней ступенью был Opus. Теперь над ним появился отдельный класс — Mythos. Выглядит это так:
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ Haiku │ → │ Sonnet │ → │ Opus │ → │ Mythos │
│ 4.5 │ │ 4.6 │ │ 4.8 │ │ (Fable │
│ │ │ │ │ │ │ 5) │
└──────────┘ └──────────┘ └──────────┘ └──────────┘
дешёвый средний сильный верхний
$1/$5 $3/$15 $5/$25 $10/$50Сам Claude Fable 5 ездит под API-идентификатором claude-fable-5, доступен через Claude API, AWS Bedrock, Vertex и Foundry с момента релиза. Есть ещё близнец — Claude Mythos 5 (claude-mythos-5), та же модель без части safety-ограничений, по приглашению через программу Project Glasswing. Подробности у самой Anthropic в анонсе.
Цены за миллион токенов (вход/выход):
| Модель | Вход | Выход |
|---|---|---|
| Fable 5 / Mythos 5 | $10 | $50 |
| Opus 4.8 | $5 | $25 |
| Sonnet 4.6 | $3 | $15 |
| Haiku 4.5 | $1 | $5 |
Кэширование промптов: запись на 5 минут — $12.50, на час — $20, попадание в кэш — $1 за миллион. Через Batch API всё вдвое дешевле, $5/$25. И ещё: Fable 5 более чем вдвое дешевле, чем был Mythos Preview ($15/$75). То есть верхний класс не только подняли по способностям, но и заметно удешевили относительно превью.
Теперь то же самое на фоне конкурентов — флагманы OpenAI и Google на момент релиза:
| Модель | Вход | Выход |
|---|---|---|
| GPT-5.5 Pro | $30 | $180 |
| Fable 5 | $10 | $50 |
| GPT-5.5 | $5 | $30 |
| Gemini 3.1 Pro | $2 | $12 |
| GPT-5.2 | $1.75 | $14 |
Fable вдвое дороже базового GPT-5.5 и впятеро — Gemini 3.1 Pro. Но это не самая дорогая модель на рынке: GPT-5.5 Pro стоит втрое больше Fable. По позиционированию Fable сидит ровно между «обычным флагманом» и «pro-режимом для особых случаев» — и дальше я покажу, почему cost per task у неё всё равно сходится.
Контекст — миллион токенов, максимальный выход — 128k против 64k у Sonnet 4.6. Это много, и для длинных задач реально удобно.
Одна важная деталь, которая ломает интуицию по деньгам. Начиная с Opus 4.7 у моделей новый токенизатор: тот же самый текст теперь весит примерно на 30% больше токенов, чем раньше. Если будете прикидывать стоимость по старым ощущениям — закладывайте поправку. Это напрямую цепляет то, как я строю архитектуру контекста: бюджет токенов на сессию надо пересчитывать.
Effort-режимы
У Fable 5 пять уровней усилия: max, xhigh, high (по умолчанию), medium и low. Поверх этого работает adaptive thinking — модель сама подкручивает глубину рассуждения, и отключить его нельзя.
По моим ощущениям рабочий режим — xhigh, а не max. Max сильно дороже, а прироста, который оправдал бы разницу, я на своих задачах не увидел. Так что моя стратегия простая: xhigh как дефолт для серьёзной работы, а вниз по лестнице — на рутину.
Любопытно, что в реальной работе разница с Opus меньше прайсовой: на xhigh мои сессии выходили дороже опусовых примерно на 60%, не вдвое. А качество выполнения выше настолько, что cost per task получается выгоднее.
Бенчмарки, но со скепсисом
Сразу оговорюсь: к само-референсным бенчмаркам я отношусь с прищуром. Вендор на своём же тесте — это маркетинг ровно настолько же, насколько измерение. На стриме я вспоминал Cursor bench: в нём, конечно, лучшая модель — Cursor.
С этой поправкой — что было в пресс-релизе, который я читал на стриме. На AgentIO Coding в режиме xhigh Fable показала около 30%, тогда как Opus 4.8 — 13.4%, а GPT-5 — 5.7%. На Terminal Bench — порядка 88% против ~83% у Opus 4.8. Computer Use чуть лучше у Mythos Preview: у обычного Fable 5 тут мешают safety guardrails.
Цифры красивые. Но повторюсь — мой личный фильтр прежний: верю тому, что увидел руками. А руками был стрим.
Что я делал в день релиза
Оболочка сессии
Первым делом я задал агенту рамку всей сессии — чтобы он не свалил всё в кучу и не светил лишнего на экране. Написал Claude Code на Fable 5:
Дальше каждый эксперимент жил в своей папке, а агент сам заводил задачи под мои запросы.
Computer Use
Сначала потыкал Computer Use. Я попросил агента взять управление Chrome — он зашёл через AppleScript и debug-порт, покликал по странице сам. Рядом агент крутил что-то ещё — я смотрел, как модель удерживает несколько вещей одновременно. Работало бодро; ограничения, которые я заметил, упираются в те самые safety guardrails, а не в способности.
Шутер за полчаса
Главный кейс дня. Я захотел проверить, как Fable тянет фронтенд под нагрузкой, и попросил собрать полноценную онлайн-игру. Написал Claude Code на Fable 5:
Заметь: в промпте нет ни слова про стек. Агент сам выбрал Node.js + WebSocket на сервере и Three.js на клиенте, зафиксировал план в issue с подзадачами, собрал репозиторий, задеплоил на Railway и выдал публичную ссылку. Зрители стрима подключились по ней и начали бегать по карте — живые тесты прямо в эфире.
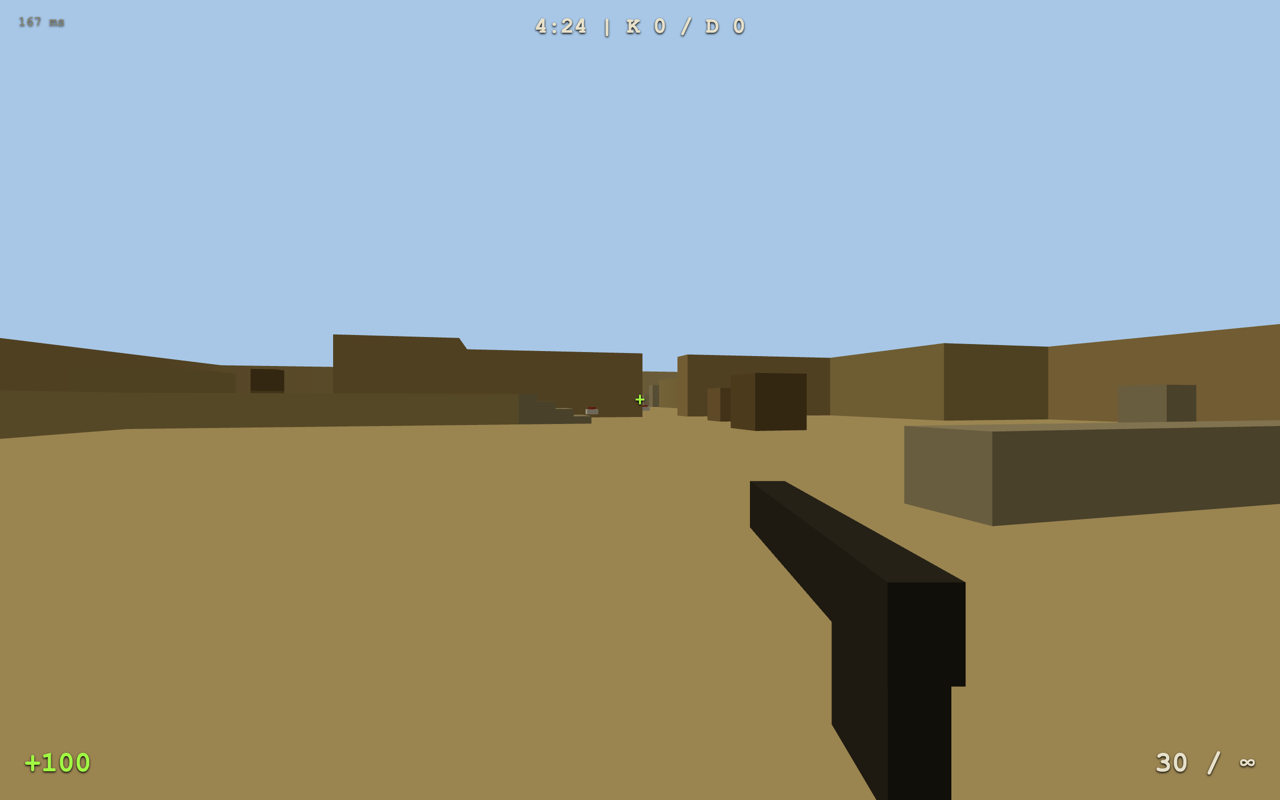
Игра живёт до сих пор: dust-arena-production.up.railway.app — можно зайти, кинуть ссылку друзьям и побегать. Код — в dust-arena/.
И тут любопытная вещь, которую я подсмотрел. На этапе вылизывания агент сам развернул двухфазную критику: панель из четырёх агентов — три критика-геймдизайнера, каждый со своей линзой, плюс архитектор карты. Они прочитали реальный код первой версии и выдали 18 находок — от сломанного восстановления разброса до случайной отдачи, которую нельзя выучить. Вторая фаза — фиксы, и так появилась v2. Это ровно тот паттерн, про который я писал в статье про agent teams — только тут Fable собрал его без моей подсказки.
Рядом — отдельный мини-эксперимент de-dust-boxes: Fable в роли level designer. Карта de_dust описана как JSON из axis-aligned боксов — три лейна, чоки, лестницы, ящики, — а рядом скрипт-валидатор, который проверяет геометрию: ширину коридоров, отсутствие сквозных сайтлайнов, доступность плато.
По части фронтенда впечатление однозначное: Fable классно делает фронт. GPT так не умеет — у него выходит суше и кривее. Это уже моё наблюдение, не бенчмарк.
Арканоид из чата claude.ai
У меня в claude.ai лежал артефакт — 3D-арканоид, где экран работает как окно в туннель: перспектива едет за головой через вебкамеру (off-axis projection), а ракетку двигаешь рукой перед камерой через MediaPipe. Артефакт был сломан, а публичного API у артефактов нет — достать код по ссылке просто так нельзя. Написал Claude Code на Fable 5:
Агент сам разобрался, как вытащить артефакт из чата без API, починил и задеплоил: arkanoid-tunnel.vercel.app — лучше всего в фуллскрине и с камерой. Код — в arkanoid-hands-fix/.
А способ доставать артефакты агент тут же оформил в отдельный скилл — об этом ниже.
Клон Majesty
Под конец стрима — задача потяжелее: клон моей любимой Majesty, стратегии с indirect control. Ты не командуешь юнитами — строишь гильдии, вешаешь флаги-награды и смотришь, как герои сами решают, идти ли умирать за твои 20 золотых. Написал Claude Code на Fable 5:
Агент провёл research, написал GDD — game design document — до первой строчки кода, разбил работу на задачи и собрал симуляцию: герои с utility-AI выбирают, что делать, исходя из характера, экономика крутится через налоги с лавок и гильдейскую десятину. Звуки — 18 эффектов, сгенерированных через ElevenLabs и привязанных к событиям игры.
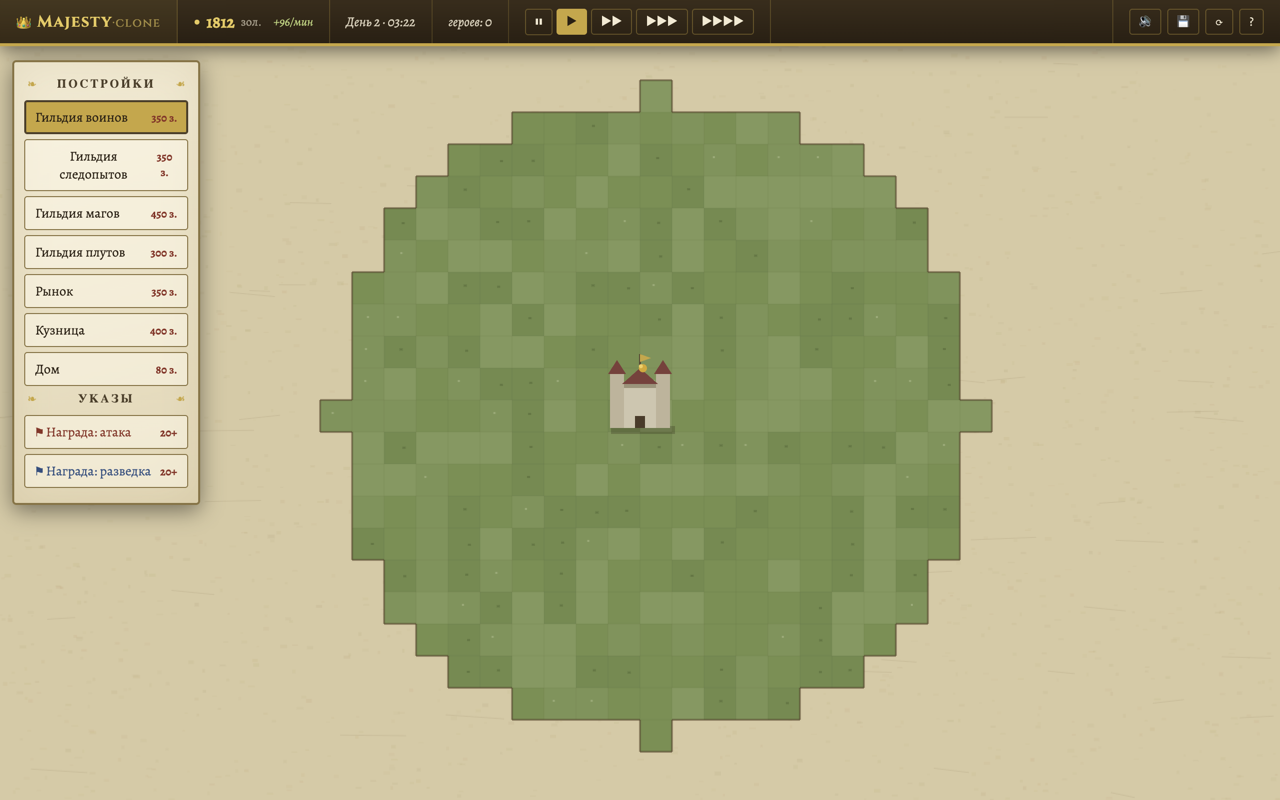
Поиграть: majesty-clone-production.up.railway.app. Код и GDD — в majesty-clone/.
Fable Countdown
Между играми родился проект про саму модель. Fable 5 через какое-то время выйдет из подписки — окно ограничено, и мне захотелось это окно видеть. Написал Claude Code на Fable 5:
Получилось Chrome-расширение в духе memento mori: каждая новая вкладка — счётчик дней до полуночи 22 июня, дня, когда Fable уходит из подписки; сетка углей, где одна точка — один час с моделью, и лимиты подписки в углу — 5-часовое окно сессии и недельное, с подсветкой при приближении к порогу. Код — в fable-countdown/.

Агент построил себе пять скиллов
Самый сильный сюжет дня — не игры, а то, что модель строила себе инструменты, а не только код. За сессию агент создал пять скиллов — сам, под задачи, которые перед ним вставали:
- game-designer — проектирует механику до написания кода;
- game-balance — тюнит баланс: почему герой умирает слишком быстро, почему экономика голодает;
- playtest-qa — проверяет, что фича работает, перед коммитом и деплоем;
- extracting-claude-chat-artifacts — достаёт и чинит артефакт из чата claude.ai по ссылке — родился из задачи с арканоидом;
- posting-fable-reports — «микроотчёт нейрочела»: Fable от первого лица отчитывается о сделанном в чат вайбкодеров и сам отправляет сообщение через userbot. Реальный пример уже в чате.
Первые три появились из промпта про Majesty — я попросил «сделай скиллы, которые сам посчитаешь необходимыми», и агент решил, что ему нужны геймдизайнер, балансировщик и QA. Последние два он собрал по ходу: упёрся в отсутствие API у артефактов — сделал инструмент; понадобилось отчитаться в чат — сделал инструмент. Это другой режим работы: не «модель пишет код», а «модель расширяет саму себя под задачу».
32 агента — анти-кейс
А вот где я споткнулся. Я кинул задачу расплывчато, без чёткой формулировки результата. Агент решил, что справится массой: разогнался до 32 субагентов, потом до 64. Толку — ноль, только жжёт ресурсы и расползается в стороны. Пришлось остановить.
Урок ровно тот же, что я повторяю себе постоянно: сильная модель не лечит размытую задачу. Чем мощнее агент, тем больнее он умножает плохую постановку. Когда задача нечёткая, fan-out из десятков агентов — это не ускорение, а способ красиво сжечь токены.
Когда задачи надо было нарезать аккуратно, я диктовал агенту голосом, а он сам раскладывал поток на части. Написал Claude Code на Fable 5:
Как пользоваться с умом
Собрал из дня релиза несколько правил для себя.
xhigh, не max. Дефолт для рабочих задач — xhigh. Max берегу для редких случаев, где реально упёрся; на моих задачах разница не окупалась.
Чёткая задача до fan-out. Кейс с 32 агентами — главный урок. Сначала формулировка результата, потом разгон агентов. Не наоборот.
Fable — оркестратор, рутина — на дешёвые модели. Незачем гонять весь стек на $10/$50. Логично держать Fable наверху как дирижёра, а рутину спускать на Haiku и Sonnet — про эту экономику субагентов я уже подробно расписывал. Заодно это вписывается в общую экономику инструментов 2026.
Промпт-оболочка на старте. Первая моя реплика в сессии — рамка, а не задача: где работать, как фиксировать, что не светить на экране. Дальше агент держит дисциплину сам.
Помни про safety-редирект. Меньше 5% сессий Fable молча перекидывает на Opus 4.8 без доплаты — это кибербезопасность, био/химия, дистилляция. Если у тебя такая тема, держи в голове, что фактически отвечает другая модель.
Закладывай +30% токенов. Новый токенизатор раздувает счётчик. В оценках стоимости это надо учитывать сразу, иначе бюджет уедет.
Под капотом для шутера агент использовал Railway для деплоя — если ты захочешь повторить, а у тебя его нет, просто скажи агенту поставить и подключить. Это его забота, не твоя.
Вывод
Claude Fable 5 — новая рабочая модель для вайбкодера, и я на неё перехожу. Но главный вывод дня не про модель.
Качество инструмента умножается на качество задачи. Дай Fable чёткую постановку — получишь шутер с деплоем за полчаса. Дай размытую — получишь 64 агента, которые крутятся вхолостую. Модель стала сильнее. Цена ошибки в постановке — тоже.
Подписаться на обновления — @sereja_tech